
When developing technologies to support surgeons in the operating room, it’s vital to rigorously evaluate new AI models, workflow optimizations, and imaging techniques in digital simulations and laboratory studies before testing them in the real world.
Led by John C. Malone Associate Professor of Computer Science Mathias Unberath, researchers from the Advanced Robotics and Computationally AugmenteD Environments (ARCADE) Lab are advancing the science of surgery by using digital twins—virtual replicas of a patient or operating room that are updated continuously with real-time data—to refine new technologies without risking patient safety.
They have constructed digital twins of operating rooms to support immersive space planning applications and digital twins of patients as a means to minimize human exposure to harmful X-rays.
Now, at the 28th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI), they’ve demonstrated how OR digital twins can help machine learning models analyze surgical videos and identify workflow bottlenecks.
For an ML model to automatically identify potential cost savings, monitor safety protocol compliance, and evaluate team coordination in an OR, it must use reasoning segmentation, or RS, to interpret high-level user commands without explicit step-by-step guidance.
Traditional RS methods rely on large language model (LLM) fine-tuning, but even state-of-the-art LLMs struggle with complex medical terminology, data variability across hospitals and health care institutions, and identifying semantic and spatial relationships when analyzing OR videos.
“Constant fine-tuning requires frequent updates to maintain compatibility with evolving models, potentially disrupting continuous monitoring and increasing implementation costs,” the researchers write.
To address this issue, Unberath and his team—CS PhD student Yiqing Shen; CS master’s student Chenjia Li; Bohan Liu, a graduate student in the Department of Electrical and Computer Engineering; alumnus Cheng-Yi “Charlie” Li, Engr ’25 (MS); and Tito Porras, a resident in the Department of Neurology and Neurosurgery at the School of Medicine—propose a new approach that preserves the semantic and spatial relationships observed in OR videos while restructuring the traditional RS approach into a “reason-retrieve-synthesize” paradigm, enabling adaptive RS without fine-tuning.
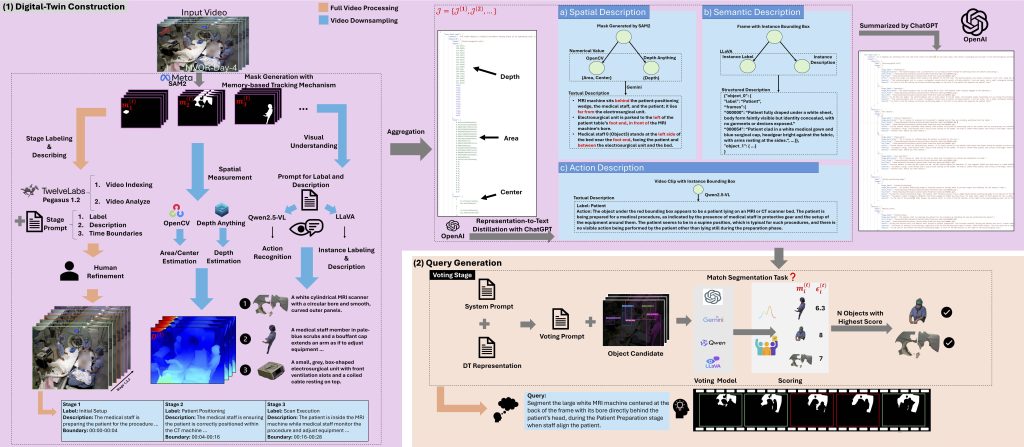
Overview of the Operating Room Digital twin representation for Reasoning Segmentation framework.
Their approach works by first interpreting a text query from the user, examining the spatial and semantic relationships between objects in a digital twin, and then generating segmentation masks to reason about these factors to satisfy the user’s query.
The team created an AI agent to break down OR workflow analysis queries into manageable RS sub-queries, generating responses that combine detailed textual explanations with visual evidence. Their agent outperformed existing models in object detection, achieving improvements of 6.12% to 9.74%.
Because of the time and computing power this approach requires, it is only suitable for offline workflow analysis tasks, which led a subset of the team—Shen, Liu, Chenjia Li, and Unberath—plus postdoctoral researcher Lalithkumar Seenivasan to suggest the more generalizable and efficient approach of creating virtual representations only as they’re needed. They presented their framework at the 2025 International Conference on Computer Vision.
Here’s how it works: Given an implicit text query, an LLM planner module analyzes the prompt and constructs a low-level digital twin from a surgical video. Unlike traditional digital twins that maintain comprehensive representations, this approach selectively generates and updates only the information required by specific queries, reducing the framework’s computational overhead.
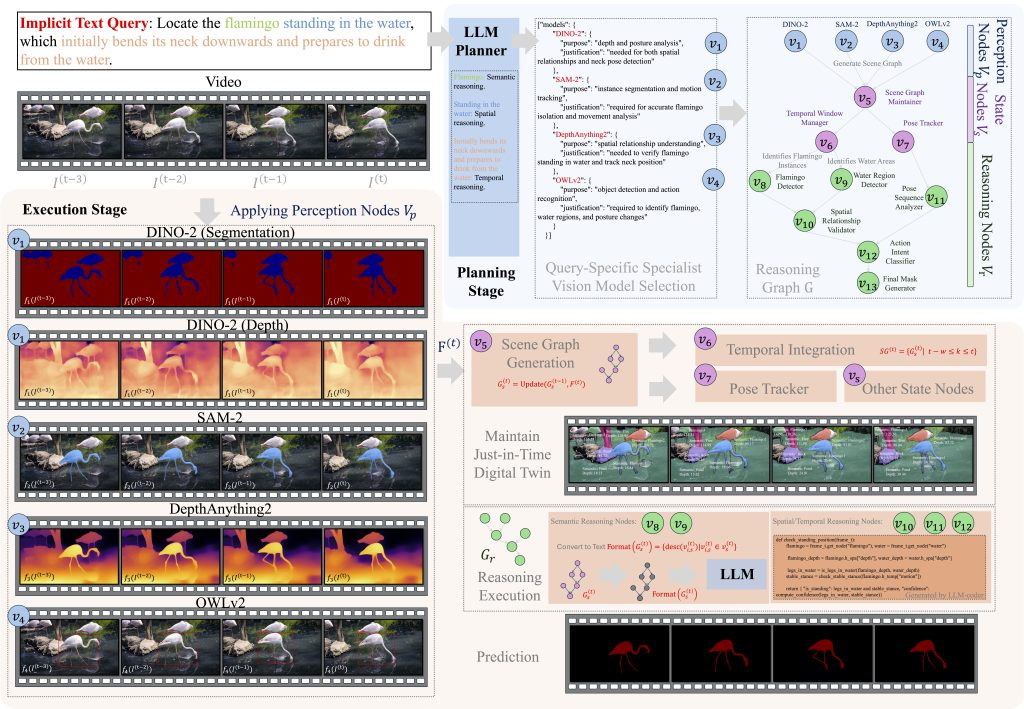
Overview of the proposed agent-based framework for video reasoning segmentation.
“This construction allows for more efficient processing of video sequences while preserving the contextual information needed for complex reasoning,” the researchers write in their study.
The team tested its method and found that it achieves consistent improvements across all categories of reasoning and difficulty levels compared to state-of-the-art approaches, meaning it can better help ML models analyze surgical videos and identify ways to improve efficiency and teamwork in the OR.
According to the researchers, both studies open new avenues for research in embodied AI and video, and could support new applications in robotics and real-world health care scenarios.