Code

Neural UMLS Concept Linker
Given a clinical note and span (mention) annotations over the note, this system normalizes each span to it's corresponding UMLS Concept with high accuracy. Elliot Schumacher, Andriy Mulyar, Mark Dredze. Clinical Concept Linking with Contextualized Neural Representations. Association for Computational Linguistics (ACL), 2020.
Cross-Lingual Entity Linker
The architecture is described in Cross-Lingual Transfer in Zero-Shot Cross-Language Entity Linking, Schumacher et al 2020 (to Appear in Findings of ACL 2021, https://arxiv.org/abs/2010.09828).

Do Models of Mental Health Based on Social Media Data Generalize?
Code and data for "Do Models of Mental Health Based on Social Media Data Generalize?" in Findings of EMNLP (2020)

semantic-text-similarity with BERT
An easy-to-use interface to fine-tuned BERT models for computing semantic similarity. This was used for our submission to the N2C2 2019 shared task. https://n2c2.dbmi.hms.harvard.edu/track1

BERT Long Document Classification for Clinical Phenotyping
An easy-to-use interface to fully trained BERT based models for multi-class and multi-label long document classification. Pre-trained models are currently available for two clinical note (EHR) phenotyping tasks: smoker identification and obesity detection. This model was used in our 2019 ML4H workshop paper: https://arxiv.org/abs/1910.13664
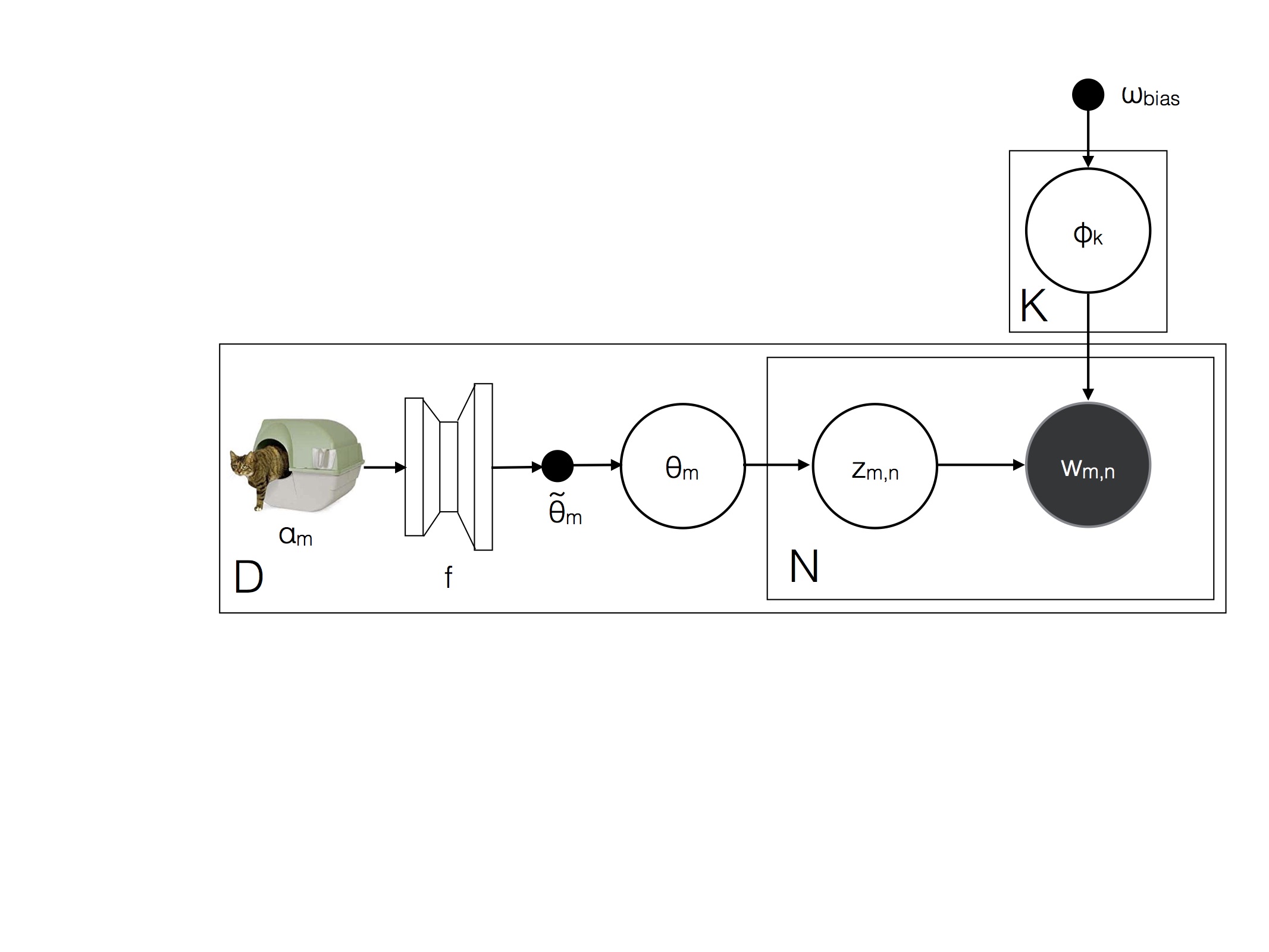
Deep DMR
Implementation of Deep Dirichlet Multinomial Regression in python + cython. Adrian Benton, Mark Dredze. Deep Dirichlet Multinomial Regression. North American Chapter of the Association for Computational Linguistics (NAACL), 2018.

Demographer: Gender Identification for Social Media
Demographer is a Python package that identifies demographic characteristics based on a name. It's designed for Twitter, where it takes the name of the user and returns information about his or her likely demographics.
SPRITE: Structured PRIor Topic modEls
A general purpose topic modeling package that implements SPRITE from our TACL 2015 paper. The package supports multi-threaded training and makes implementing new models easier:
Michael J Paul, Mark Dredze. SPRITE: Generalizing Topic Models with Structured Priors. Transactions of the Association for Computational Linguistics (TACL), 2015.
This also contains a detailed readme and tutorial (see Wiki) on how to use the code.
PARMA: A Predicate Argument Aligner
PARMA is our predicate argument aligner: Travis Wolfe, Benjamin Van Durme, Mark Dredze, Nicholas Andrews, Charley Beller, Chris Callison-Burch, Jay DeYoung, Justin Snyder, Jonathan Weese, Tan Xu, Xuchen Yao. PARMA: A Predicate Argument Aligner. Association for Computational Linguistics (ACL) (short paper), 2013.

Confidence Weighted Learning Library
We have collected most of the core algorithms in the confidence weighted learning framework for release as a software library. Please email me for the code.

Golden Horse
Code for named entity recognition using embeddings, focused on Chinese social media (Weibo). This code implements the methods in our paper: Nanyun Peng, Mark Dredze. Named Entity Recognition for Chinese Social Media with Jointly Trained Embeddings. Empirical Methods in Natural Language Processing (EMNLP) (short paper), 2015.

Carmen: Geolocation for Twitter
Carmen is a library for geolocating tweets. Given a tweet, Carmen will return Location objects that represent a physical location. Carmen uses both coordinates and other information in a tweet to make geolocation decisions. It's not perfect, but this greatly increases the number of geolocated tweets over what Twitter provides. The Python and Java versions don't give exactly the same results due to differences in the dependencies. If you use Carmen, please cite: Mark Dredze, Michael J Paul, Shane Bergsma, Hieu Tran. Carmen: A Twitter Geolocation System with Applications to Public Health. AAAI Workshop on Expanding the Boundaries of Health Informatics Using AI (HIAI), 2013.

Twitter Stream Downloader
Code for downloading data using the Twitter streaming API.

Mingpipe
Code for Chinese name matching. Given two Chinese person names, assigns a score based on how likely the two names refer to the same person.

csLDA
Cross language topic models based on code-switched documents. Documents can be in different languages and some "glue" documents contain multiple languages. csLDA learns topics for each language and aligns topics across languages.

Multiview Representations of Twitter Users
Code and data for our paper: Adrian Benton, Raman Arora, and Mark Dredze. Learning Multiview Representations of Twitter Users. Association for Computational Linguistics (ACL), 2016.
Automated Reviewer Assignment (used in multiple ACL affiliated conferences)
I authored a process for automatically assigning reviewers to an area for ACL affiliated conferences. The code is freely available for others to use. Let me know if you plan on using this system; I'm happy to answer questions.
