CLEVR-Ref+: Diagnosing Visual Reasoning with Referring Expressions
In this project we construct the CLEVR-Ref+ dataset, by repurposing and augmenting the CLEVR dataset from VQA towards referring expressions. This synthetic diagnostic dataset will complement existing real-world ones:

There are two main reasons we did this:
-
One is to test and diagnose state-of-the-art referring expression models at a more detailed level than the detection accuracy or segmentation IoU, including our proposed IEP-Ref model that explicitly captures compositionality.
-
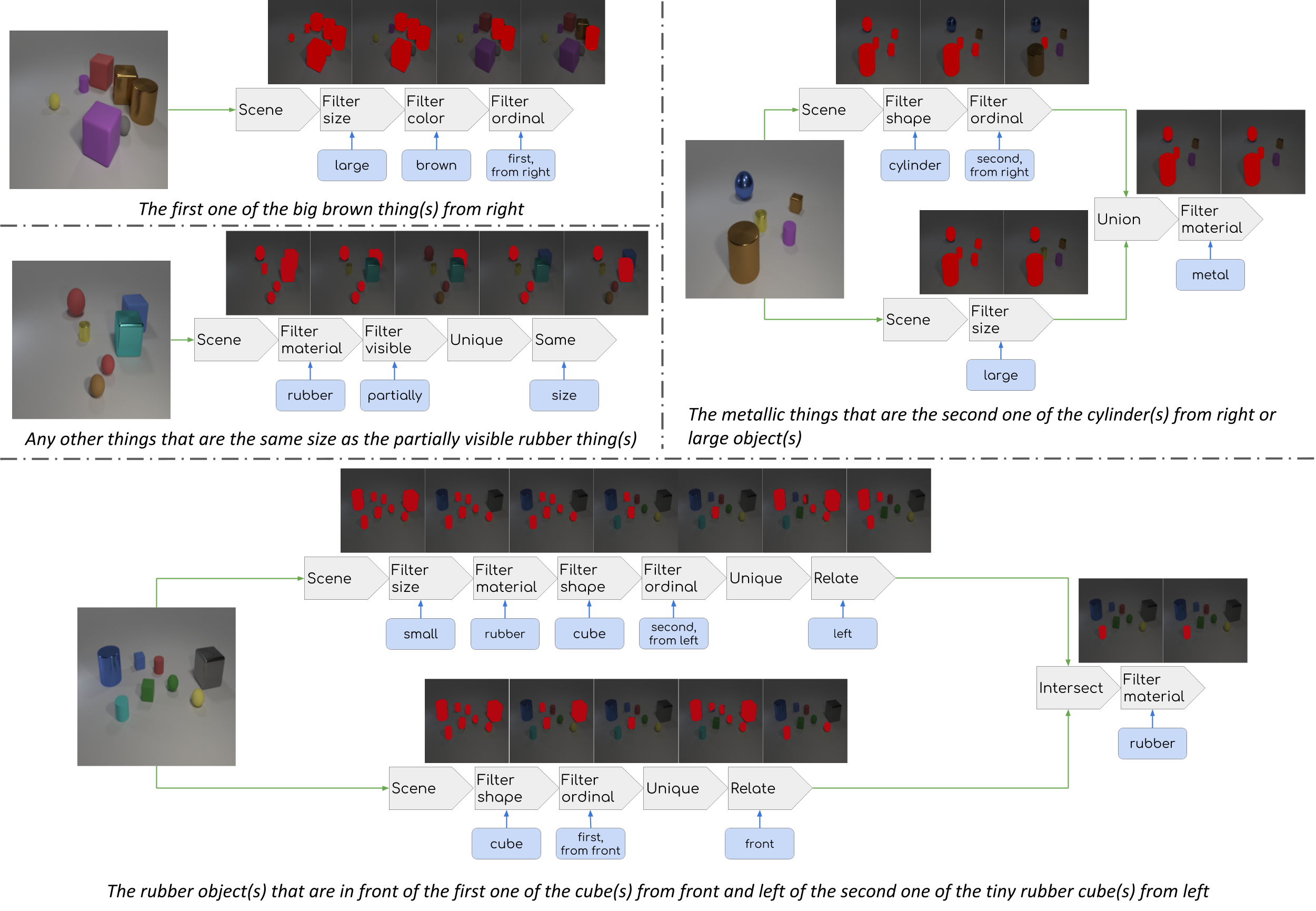
The other is to perform step-by-step inspection of the model’s reasoning process. We are especially interested in whether the neural modules in Neural Module Networks indeed perform the intended functionalities when trained end-to-end. According to our experiments, the answer is quite positive:
Download Links
[CLEVR-Ref+-v1.0 Dataset (16GB)]
[CLEVR-Ref+-CoGenT-v1.0 Dataset (19GB)]