Pictures
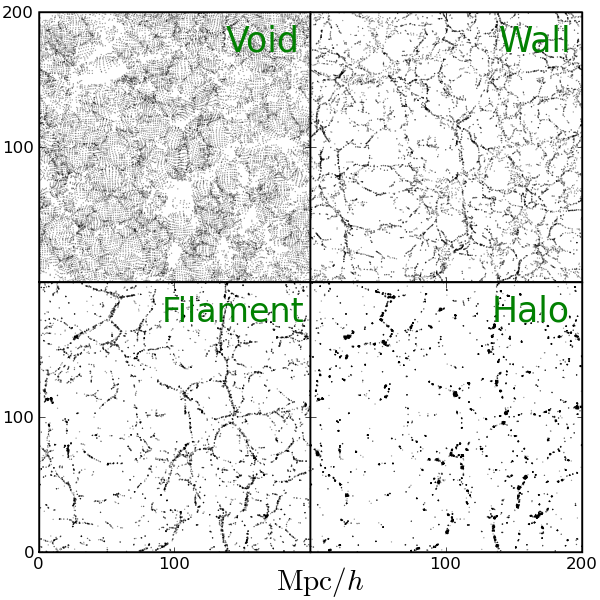
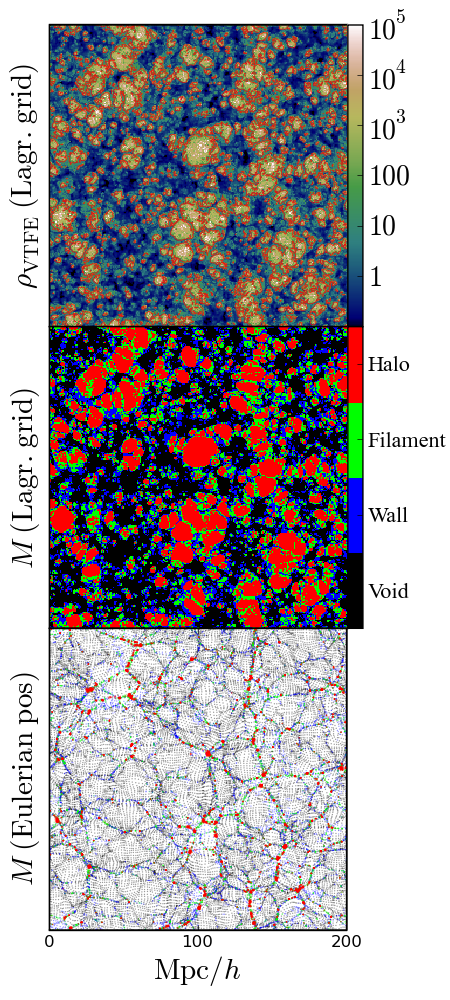
What do "Haloes" look like?
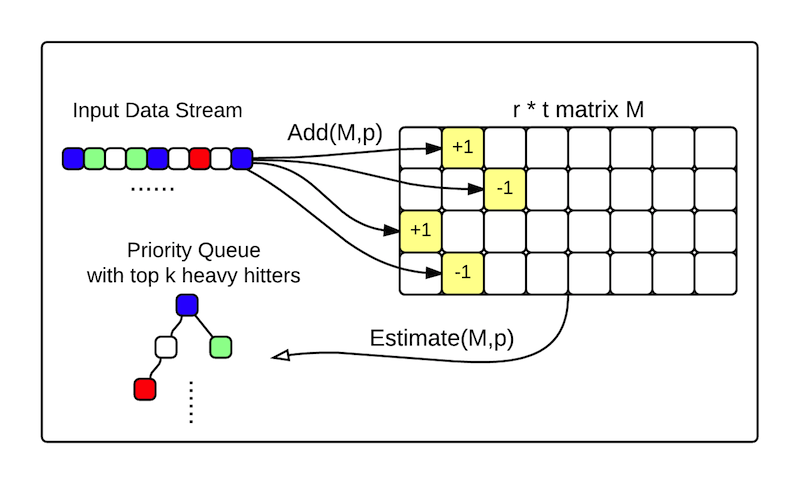
What do "Heavy Hitter" algorithms look like?

Principal Investigators:
Research Scientists:
Students:
Streaming Algorithms for Halo Finders
Zaoxing Liu, Nikita Ivkin, Lin F. Yang, Mark Neyrinck, Gerard Lemson, Alexander S. Szalay, Vladimir Braverman, Tamas Budavari, Randal Burns, and Xin Wang
Proceedings of 11th IEEE International Conference on E-Science, eScience 2015
New Bounds for the CLIQUE-GAP Problem using Graph Decomposition Theory
Vladimir Braverman, Zaoxing Liu, Tejasvam Singh, N.V. Vinodchandran and Lin Yang
Proceedings of 40th International Symposium, Mathematical Foundations of Computer Science (MFCS 2015)
Zero-One Laws for Sliding Windows and Universal Sketches
Vladimir Braverman, Rafail Ostrovsky and Alan Roytman
19th International Workshop on Randomization and Computation (Random 2015)
Universal sketches for the frequency negative moments and other decreasing streaming sums
Vladimir Braverman and Stephen Chestnut
19th International Workshop on Randomization and Computation (Random 2015)
Weighted Sampling Without Replacement from Data Streams
Vladimir Braverman, Rafail Ostrovsky, Gregory Vorsanger
Information Processing Letters Journal
This is a preliminary version and we keep updating it. Version 1.0 ---OpenMP enabled
Count-sketch based Halo Finder (cs.tar.gz)
Pick-and-drop based Halo Finder (pd.tar.gz)
What do "Haloes" look like?
What do "Heavy Hitter" algorithms look like?
We gratefully acknowledge the support and help from
